所以,QQWorld收藏家 v2.2.3 Beta14 新增魔法采集:AJAX采集者。下面来介绍这个通用魔法采集是如何采集AJAX加载的网站的。
准备工作
- QQWorld收藏家旗舰版
- 要采集的网站列表页:http://web.fzmnice.net/index.php?c=article&m=lists&classId=16&u=1060505161
新建收藏项目
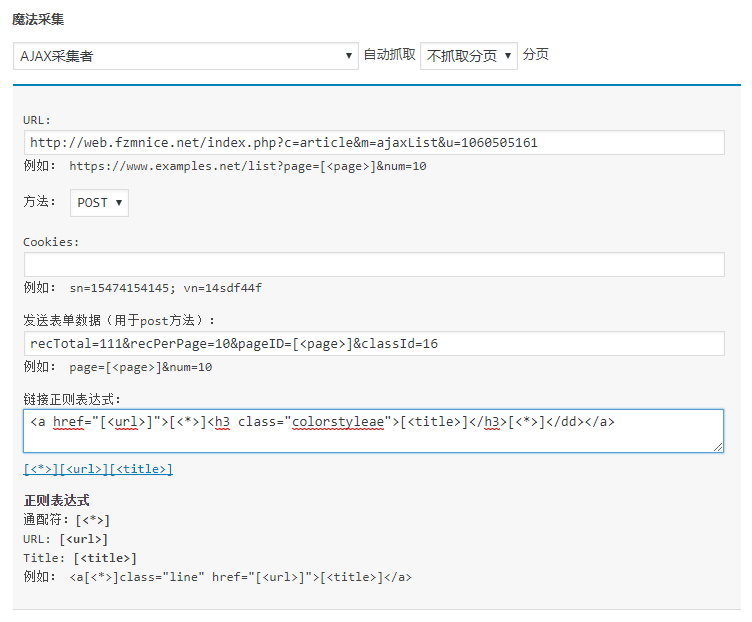
在QQWorld收藏家中新建空收藏项目,写上标题 复制猫 fzmnice.net。然后在来源地址采集面板中的魔法采集菜单中选择AJAX采集者,弹出下面的设置面板。
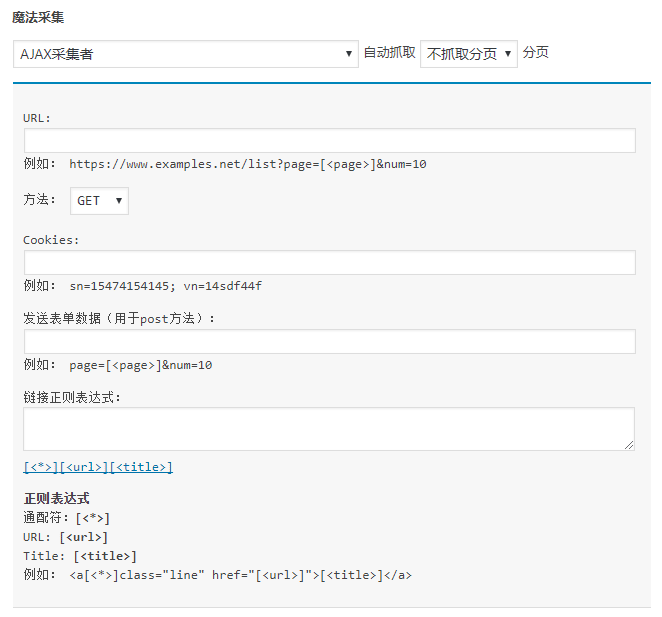
共有6处可以设置,分别是:
- 自动抓取的分页数:不抓取分页则只采集1页,如果设置抓取1个分页,就会共抓取2页。
- URL:AJAX的请求地址,可使用变量 [<page>] 来代表分页编号。
- 方法:有GET和POST两种,大多数情况下使用GET即可。
- Cookies:只有极少数AJAX请求需要带Cookies。
- 发送表单数据(用于post方法):少数AJAX请求是使用POST方法,这里放POST的数据,同样可以使用 [<page>] 变量。
- 链接正则表达式:用来获取返回结果中的文章地址和标题,标题并不是必须的。
操作实例
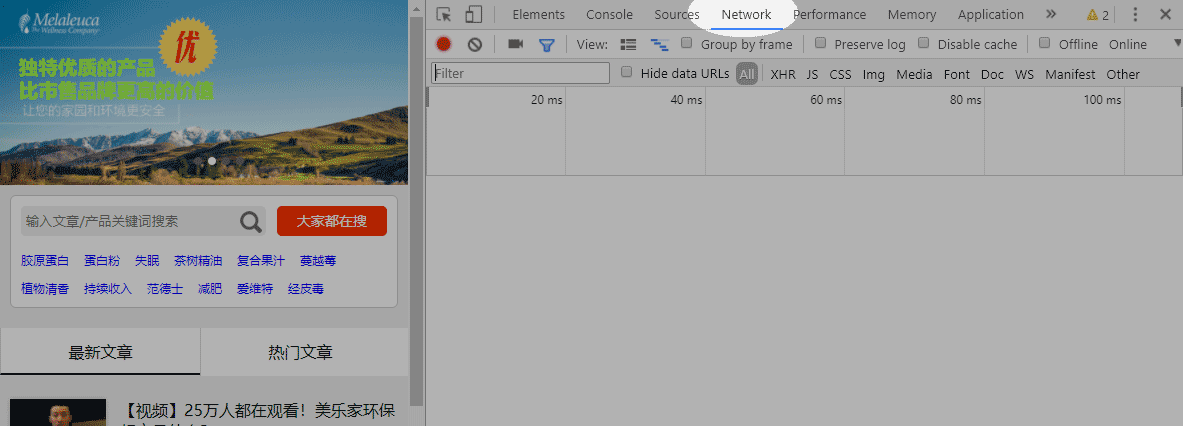
在Chrome浏览器中打开之前准备好要采集的网站列表页,按F12调出开发者工具,然后切换到Network选项卡。
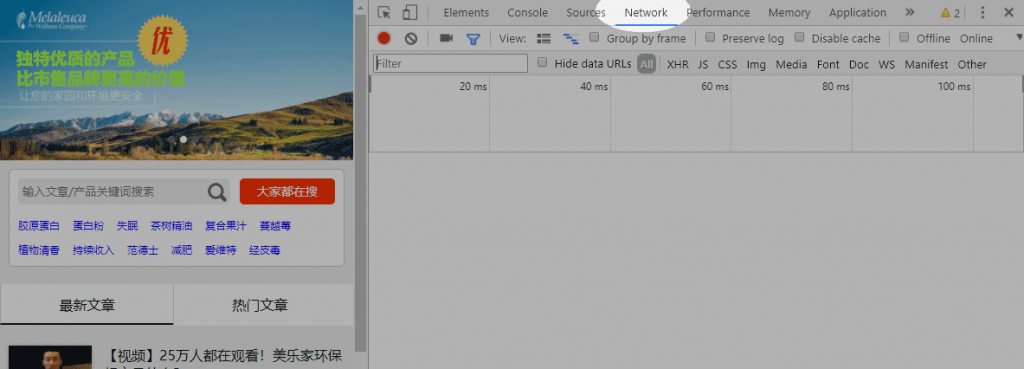
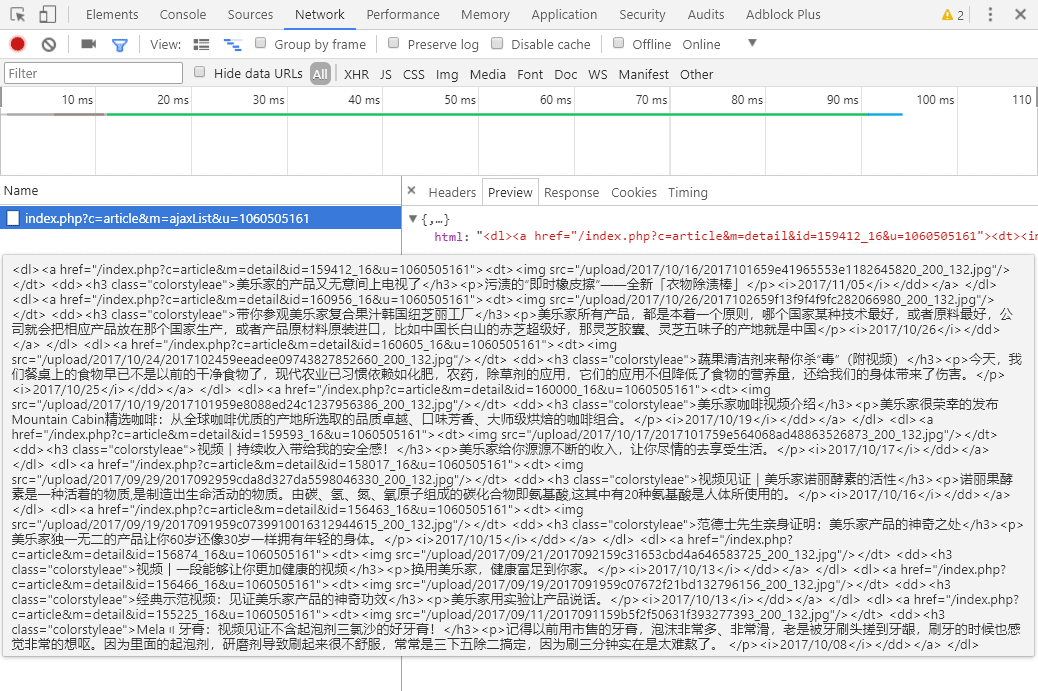
然后将网页向下滚动,直到自动加载下一页。这时,Network选项卡中就会检测到新的网络请求,点击改请求,在右侧的Preview选项卡中可以看到正是下一页的数据,将这些数据复制到一个文本文件中保存好。
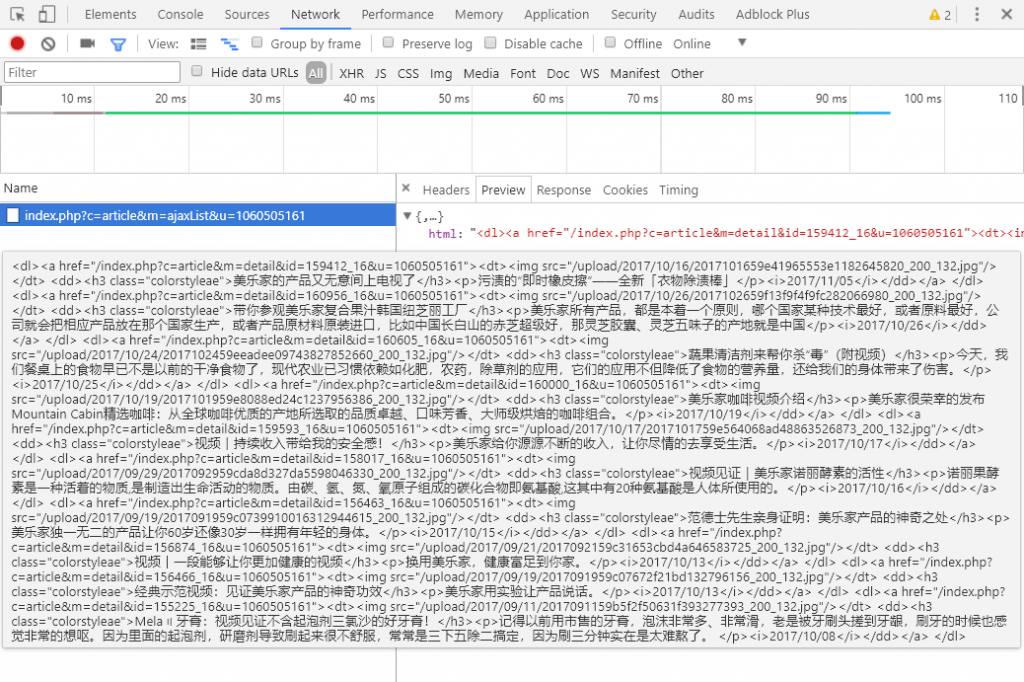
然后点击旁边的Headers选项卡,搜寻以下重要数据:

从上到下依次是:AJAX的请求地址、方法、Cookies和POST数据。在POST表单数据中,pageID 很明显就是页码的变量。
我们将这些数据按照范例的规格填到魔法采集AJAX采集者的表单中去。一般来说不需要用到Cookies,除非采集不到才需要尝试填Cookies:
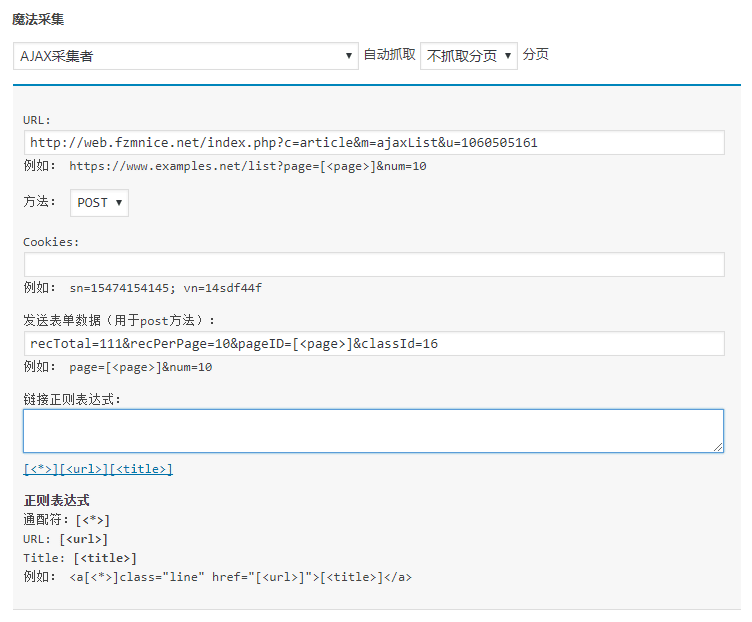
最后一步,在获取到的内容中抓取文章链接和标题。找到其中循环的规则:

将这个规则复制到链接正则表达式中,将其中关键性的内容替换成通配符和变量,比如:
<dl><a href="/index.php?c=article&m=detail&id=159412_16&u=1060505161"><dt><img src="/upload/2017/10/16/2017101659e41965553e1182645820_200_132.jpg"/></dt> <dd><h3 class="colorstyleae">美乐家的产品又无意间上电视了</h3><p>污渍的“即时橡皮擦”——全新「衣物除渍棒」</p><i>2017/11/05</i></dd></a> </dl>
替换成
<a href="[<url>]">[<*>]<h3 class="colorstyleae">[<title>]</h3>[<*>]</dd></a>
最终的设置效果是:
测试采集
点击测试获取链接按钮,成功获取到了文章链接。








{kind=link}
{kind=link}
新魔法采集:QQWorld收藏家采集AJAX加载的网站 有 3 篇评论
这个功能挺赞!!!
您好我自动采集不会用,能否与您联系一下啊
可以,请联系客服。